
In this article I will explain the concept of iterators, in the context of the query execution plan.
First, you will find out what they are. Second, I will tell you what are the main actions performed by an iterator. And last, but not least, I am going to show you how they work in practice.
What are Iterators?
The definition says that an iterator (or operator) is the fundamental building block of a query.
What does this mean? It means that an iterator is an object that performs a single operation. For example, it can whether scan data from a table or update data in a table, but it can never do both.
So one single database operation per iterator, that’s the definition we should remember.
You can imagine that a single operator is not very useful. Nobody usually performs a single operation.
This is why the iterators are combined in trees, which are called query plans. A query plan consists of many iterators (or operators), each doing its own job.
Because a query plan is a tree structure, an operator can have children (zero or more).
SQL Server tries to optimize each query, which means it tries to find the best combination of iterators for a specific query that will make it perform the cheapest or the fastest.
What does an iterator do?
There are three things that each operator does:
- First, it reads the input rows. The rows can come from either a data source or from the operator’s children.
- Then, it does some processing to the rows. This can mean a different thing, based on the type of the iterator.
- And finally, it returns the output to its parent.
Types of processing
There are two types of processing that can be performed by iterators:
- One row at a time (or row-based processing), which means that the operation specific to that iterator will be applied for each row that enters the iterator
- And batch-mode processing. This is an approach introduced in SQL Server 2012, where operators process the entire batch of rows instead of one row at a time.
Row-Based Model
Iterators are code objects, which share a common interface of methods and properties. The most frequently used of these are the methods used to process rows, set and retrieve property information, and produce a cost estimate for the optimizer to use.
In the row-based model, all iterators implement the same set of core methods, which are:
- Open (a method that announces the operator that it’s time to start producing output rows)
- GetRow (which requests the operator to produce a new row)
- And the Close method, that indicates that the iterator’s parent has finished requesting rows.
Because all iterators have the same structure, it means that they can work independently one of the other.
Let’s take a look at a query plan now, to see one or more iterators and how they combine.
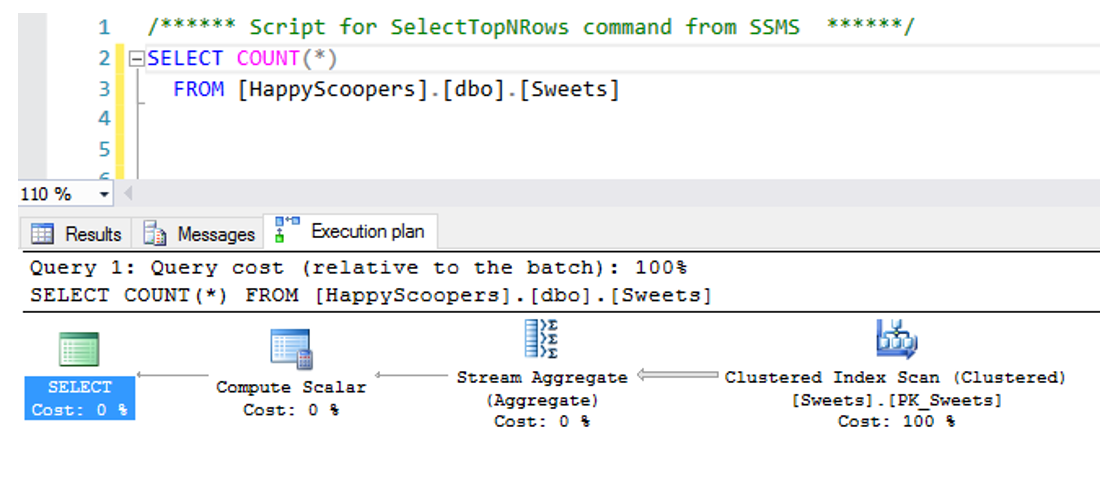
If I perform, for example, a SELECT COUNT(*) FROM Products, this is how my plan looks like.
If this is not familiar to you right now, don’t worry, it will all start to make more sense after a few more clips.
There are two different ways to read the plan:
- Following the control flow, from left to right. This means that the methods Open, GetRow and Close are called starting with the root node of the query tree and the results are propagated down to the leaf iterators.
- And following the data flow, which is from the bottom right corner to the top left. This the the way data is retrieved.
So back to our example. For counting all the rows in my Products table, two operators will be used:
- One that gets all the rows from the table. This means that the Products table will be scanned.
- And one that counts them. As I said earlier, you can only do a single operation per operator.
What is happening here?
Let’s look at a picture with the order of operations and you will find below the description of each step:
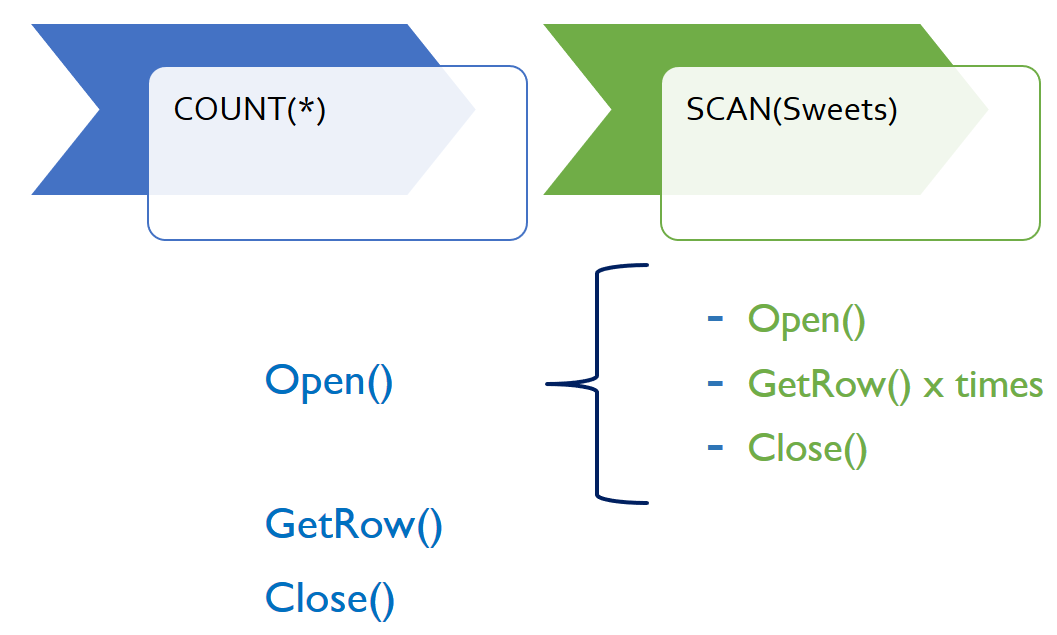
- First, SQL Server calls Open on the root iterator in the plan, which in this example is the COUNT(*) iterator. The COUNT(*) iterator performs the following tasks in the Open method:
a. It calls Open on the scan iterator, which tells the scan that it’s time to produce rows.
b. It calls GetRow repeatedly on the scan iterator, counting the rows returned, and stopping only when GetRow indicates that it has returned all the rows.
C. It calls Close on the scan iterator to indicate that it has finished getting rows. - When it returns from the Open method of the COUNT(*) iterator, we already know the number of rows in the Products table.
- Then, GetRow method of COUNT(*) gets executed and returns a result.
- Because SQL Server doesn’t know that COUNT(*) produces a single row, another GetRow method call follows. For what it’s worth, it’s an operator just like all others, that processes all rows until there are no more.
- In response to the second GetRow call, the COUNT(*) iterator returns that it has reached the end of the result set. Finally, this means a call of the Close method. The COUNT(*) iterator neither cares nor needs to know that it’s counting rows from a scan iterator. It will count rows from any subtree that SQL Server puts below it, regardless of how simple or complex the subtree might be.
Ok, now that we’ve clarified what iterators are, how they work and interact with each other, let’s find out what are their properties which we should follow when investigating query performance.
Check out my next tutorial for information about the properties of iterators.
If you have suggestions or feedback, you want me to explain something or you just want to say hi, you can do that in the comments below. I will happily answer you.
PS: Check out this MSDN article to have a better understanding of iterators and how they work: https://msdn.microsoft.com/en-us/library/ms191158.aspx